Что такое serverless технологии
Всем привет!
Надеюсь вы готовы сделать шаг в будущее? Будущее DevOps-а и, скорее всего, вашей будущей жизни в качестве фул-стек разработчика? Конечно, я немного преувеличиваю, но serverless (переводится как «бессерверные») технологии заслуживают внимание.
Данный выпуск - первый по serverless в блоге, с другими постами по теме вы можете ознакомиться по ссылкам ниже:
Серия статей:
- Что такое serverless технологии (Этот пост)
- Создаем телеграм бота с помощью serverless на nodejs
- Использование AWS Lambda с TypeScript
Наш план на сегодня:
- Разберемся что это за зверь, поговорим о том, как работают «бессерверные» приложения и что с их помощью можно создавать.
- Узнаем плюсы и минусы облачных функций (в частности, AWS-лямбд)
- Рассмотрим одноименный с технологией фреймворк serverless и создадим нашу первую лямбда-функцию.
- В заключении рассмотрим, для чего еще применимы лямбды.
Что такое serverless? AWS Lambda? #
Есть много решений, как платных, так и опенсорсных, но мы будем рассматривать только AWS и serverless, как самые популярные решения в этой области.
Начнем с того, что можно понимать под «облаками» и облачными вычислениями? Это модель обеспечения удобного доступа к вычислительным ресурсам, которые поставляет поставщик (например, амазон) и отвечает за запуск вашего кода, распределение ресурсов (масштабирование), мониторинг и т.д. Бессерверные вычисления - это модель выполнения облачных вычислений, в которой нам, разработчикам, совсем не нужно думать о серверах - всю работу с ними берет на себя поставщик услуг.
Вы сейчас можете сказать: «wft, какая же это бессерверная технология, если все запускается на серверах?». Конечно же, она не такая уж и бессерверная, ваш код будет запускаться серверах, но как там все устроено?
Мы написали функцию, загрузили ее на сервер (об этом чуть ниже). При возникновении какого-нибудь события (event) она запускается на серверах в контейнере (например, в докере). Эта функция в контейнере и называется лямбдой-функцией или просто лямбдой. Лямбды являются основной единицей данной архитектуры и выполняют определенную задачу в контейнерах, которые не доступны конечному пользователю. Пользователь можно только задеплоить функции и подключить к ней источники событий.
Опять вопрос из зала: «В чем суть, зачем нам запускать какую-то функцию в контейнере?»
Сейчас разложим все по полочкам и рассмотрим подробнее процесс работы лямбд. Схематично лямбду можно представить так:
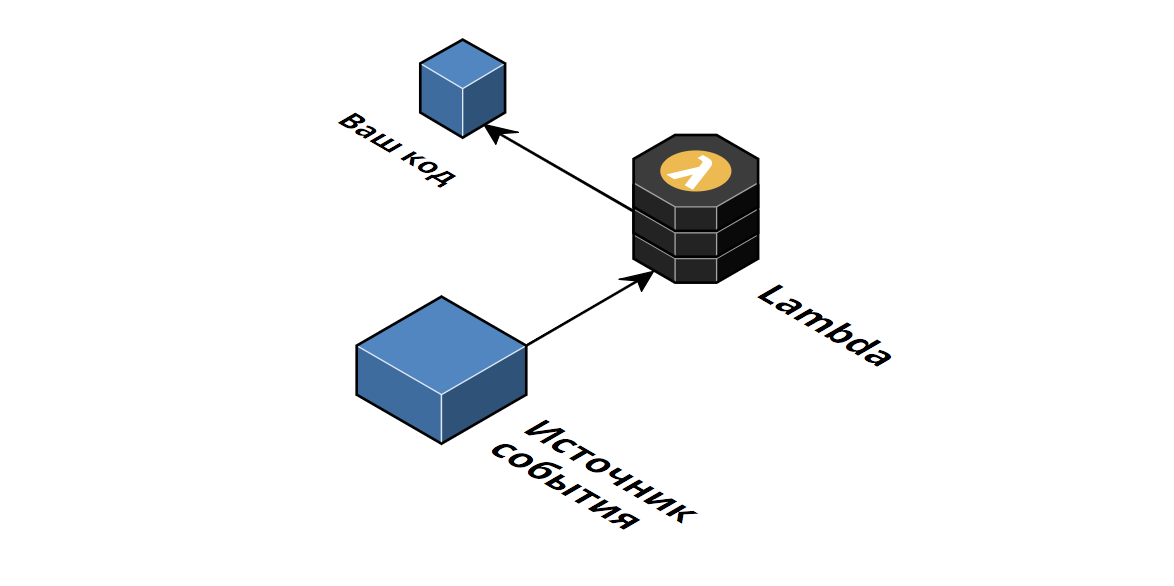
Как только вы загружаете код функции в AWS (ее можно загрузить разными способами, сразу написав ее в онлайн IDE, загрузить с помощью AWS CLI или использовать фреймворк, который поможет загрузить проект одной командой), он сохраняется в качестве пакета на внутренних серверах амазона. В момент получения события (например, http-запрос), автоматически запускается контейнер с определенным интерпретатором (или виртуальной машиной, в случае java; Да-да, лямбда это не только javascript, на ней можно запускать код на разных языках, таких как golang, .net, java, python и nodejs), который выполняет полученный код, подставляя тело события в качестве первого аргумента:
/* Пример самой простой лямбды */
module.exports.handler = (event, context, callback) => {
const response = {
statusCode: 200,
body: '<h1>Hello, Lambda</h1>'
};
callback(null, response);
};
Источником событий могут быть самые разные сервисы (в рамках амазона, это их же сервисы):
- Например при добавлении/удалении файла в S3 (файловое хранилище)
- При изменении данных в таблице DynamoDB (база данных от амазона)
- При использовании планировщика задач
- И то, что нам будет интереснее всего - это API Gateway, который позволяет обрабатывать http запросы и абстрагировать их до события для лямбды.
В случае лямбды мы можем совсем не думать о серверах. Мы работаем с лямбдой не так, как мы работаем с обычными серверами. Как работает обычное приложение на Nodejs? Мы запускаем http-сервер, который слушает указанный порт. Как только прилетает запрос, мы начинаем его обработку. К вам скорее всего закрались сомнения, что на каждый запрос поднимать свой контейнер и запускать сервер заново плохая идея, и на это будет уходить довольно много времени. Это был мой первый вопрос, когда я познакомился с serverless: как же на нем запустить http-сервер?
Тут вступает такое понятие, как время холодного старта. Это время, которое необходимо для первого (или если лямбда долго не вызывалась) запуска контейнера и приложения. Для лямбд на Nodejs оно не так уж и велико, и составляет обычно менее 400 мс (по сравнению, например с Java или C#, которые требуют 5-6 секунд. Вы можете почитать материал, где описано, как можно получить это значение). Самое интересное, что когда возникает второе событие, контейнер от первого может еще быть активным и переиспользовать загруженные в память модули или даже контейнеры (которые после выполнения функции еще живут какое-то время).
Это в свою очередь говорит о том, что в лямбде нельзя использовать механизм кеширования, а именно засорять глобальную область видимости, потому что следующая лямбда может использовать эту область видимости от предыдущей.
Если это для вас проблема (400 мс), то функции можно разогревать, например, каждые N секунд создавать событие для запуска функции.
Для каждого нового обработчика нужно создавать новую лямбду, что очень похоже на микросервисную архитектуру. Из этого принципа вытекает, что лямбда-функции не могу иметь состояния (они stateless). Благодаря этому при возникновении нагрузки и количества запросов без проблем происходит горизонтальное масштабирование.
Еще одно преимущество - это способ оплаты - pay-as-you-go. Он означает, что оплата за использование производится по времени выполнения конкретной функции. Вместо запущенного сервера 24/7, вы можете размещать функции-лямбды, и сервер будет работать только в течении жизненного цикла запроса. Это отлично подходят для прототипирования, так как платите за количество конкретных запросов, а в случае, если используете AWS Lambda, то у вас в наличии 1 миллион бесплатных запросов в месяц.
Давайте соберем все достоинства такой архитектуры вместе:
- Простота создания и развёртывания продукта. Нет необходимости думать о настройке и управлении серверами - мы можем полностью забыть об этом, и сосредоточится на бизнес-логике приложения;
- Горизонтальное масштабирования и высокая доступность проекта из коробки. И не важно, если завтра на ваш сайт придет пару человек или миллион, все будет работать как часы (По умолчанию в амазоне стоит ограничение на 100 одновременно выполняющихся функций, которое сделано с целью защиты от непреднамеренного вызова функций в процессе тестирования, но которое можно увеличить через консоль AWS);
- Оплата только за использованное время;
- Интеграция почти со всеми сервисами амазона (DynamoDB, Alexa, S3, API Gateway итд), которые позволяют обработать очень многие кейсы.
К минусам же можно отнести:
- Холодный старт контейнера, который мы рассмотрели выше;
- Отсутствие «целостности» приложения: каждая функция – это независимый объект. И если ваше приложение требует использование много функций, то нужно хорошенько подумать над архитектурой;
- Ограничения по размеру кода функции уставлено в 50 Мб. Сможете написать такую функцию? Не думаю :) Но не стоит забывать про node_modules, которая разрастается молниеносно и можно запросто перейти лимит;
- Ограничения по времени выполнения. По умолчанию лямбда выполняется всего одну секунду и если функция не ответит за это время, то в ответ клиент получит ошибку с «таймаутом». В настройках это время можно увеличить до пяти минут и для обычно сайта этого времени достаточно. Но как вы могли догадаться, это проблема, если необходимы реалтаймовые приложения, которые, например, используют websocket-ы;
- Количество параллельных функций в минуту. Ограничение по максимальному количеству равно 500-3000 (в зависимости от региона) одновременно-выполняющихся функций в минуту.
Если минусы не попадают под специфику вашего приложения, то возможно лямбды - это именно то, что вам нужно. Технология просто идеально подходит для начального этапа стартапов и блогов, однако несколько моих знакомых работали над проектами, которые действительно были высоконагруженными и использовали лямбды.
Первая лямбда с serverless #
Как мы уже выяснили, одним из минусов бессерверных технологий является сложный контроль всех компонентов. Когда лямбд становится больше десятка, а логика сложнее, чем «Hello World», управлять событиями, кодом функций, ролями пользователей становится очень непросто. Еще одним минусом лямбд в aws является то, что создатели не подумали, как ее тестировать и дебажить локально.
Для удобной конфигурации компонентов можно воспользоваться фреймворками. Самым популярным и одновременно гибким и простым решением будет одноименный с технологией фреймворк serverless. Он позволяет запускать все локально (используя плагин) и описать все интеграции и инфраструктуру проекта в одном yml-файле. Его можно использовать не только для nodejs, и не только для AWS, но мы рассмотрим именно такой вариант использования.
«Serverless» не единственный фреймворк, но у него, кроме сообщества и хорошей поддержки, есть «киллер фича» - крутая экосистема плагинов. Уже написано огромное количество разных плагинов, но даже если вы не найдете нужного, написать свой не составит никакого труда.
Приступим? #
Перед началом у вас должен быть аккаунт в AWS с админским доступом или специальный пользователь с нужными правами (при неверно выданных правах все может работать не так, как нужно); бесплатно создать его можно тут. И установлена Nodejs v8 и выше.
Создадим лямбду, которая отрендерит нашу HTML-страницу. Первым делом установим глобально фреймворк:
npm install -g serverless
Далее создадим директорию для нового проекта и сгенерируем лямбду по уже готовому шаблону. Разработчики «Serverless» сделали возможность создавать сервисы из шаблонов, создав все необходимые файлы. В данном случае я использую темплейт aws-nodejs, который создаст функцию и конфигурационный файл serverless.yml:
mkdir lambda-demo
cd lambda-demo
sls create --template aws-nodejs
npm install
Сама функция находится в файле handler.js. Давайте немного отредактируем его:
module.exports.hello = async event => {
return {
statusCode: 200,
headers: { 'Content-Type': 'text/html;charset=UTF-8' },
body: '<html><h1>Hello, Lambda</h1></html>',
};
};
Точка доступа принимает два аргумента (если она написана с использованием async/await, иначе у функции появляется третий аргумент callback):
event— данные события, вызвавшем функцию. В случае с использованием AWS API Gateway этот объект будет содержать данные по HTTP-запросу.context— объект, содержащий информацию о текущем состоянии окружения (данные о функции, информацию о пользователе и т.д.).сallback— функция форматаcallback(error, data), возвращающая результат событию, если использована не «асинхронная» функция (имеется ввиду неasync/await).
И немного подправим serveless.yml:
service: aws-nodejs # Название вашей лямбды
provider:
name: aws
runtime: nodejs8.10
stage: dev # Название этапа (любое значение, имеющее для вас какое-то значение)
region: us-west-2 # Регион Амазона, который установлен у вас
functions:
hello:
handler: handler.hello
# События, которые запускают лямбду, в нашем случае - http api-gateway
events:
- http:
path: hello
method: get
В больших проектах значение stage обычно равно ${env:AWS_STAGE, '${opt:stage, 'dev'}'} (либо просто ${opt:stage, 'dev'}), что позволяет считывать значение stage как с переменной окружения, так и с консоли (причем по умолчанию он будет установлен в dev):
// Деплой функции на другой стейджинг
sls deploy --stage test
Думаю по комментариям все более менее понятно (более подробно о конфигурации можно почитать на официальном сайте фреймворка), поэтому пойдем дальше.
Для запуска функции локально можно воспользоваться следующей командой:
serverless invoke local --function hello
В результате в ответ мы увидим результат работы функции:
{
"statusCode": 200,
"headers": { "Content-Type": "text/html;charset=UTF-8" },
"body": "<html><h1>Hello, Lambda</h1></html>"
}
Конечно мы бы хотели увидеть не код страницы, а саму страницу. Для этого нужно задеплоить функцию, или можно запустить локально с помощью плагина serverless-offline, который запустит вашу лямбду на каком-нибудь порту.
Деплой #
Запускаем:
sls deploy
В результате в консоли мы увидим следующее:
Serverless: Packaging service...
Serverless: Excluding development dependencies...
Serverless: Creating Stack...
Serverless: Checking Stack create progress...
.....
Serverless: Stack create finished...
Serverless: Uploading CloudFormation file to S3...
Serverless: Uploading artifacts...
Serverless: Uploading service aws-nodejs.zip file to S3 (10.17 KB)...
Serverless: Validating template...
Serverless: Updating Stack...
Serverless: Checking Stack update progress...
..............................
Serverless: Stack update finished...
Service Information
service: aws-nodejs
stage: dev
region: us-east-2
stack: aws-nodejs-dev
resources: 10
api keys:
None
endpoints:
GET - https://XXXXXXX.execute-api.us-east-1.amazonaws.com/dev/hello
functions:
hello: aws-nodejs-dev-hello
layers:
None
И у нас есть открытый наружу url, по которому можно вызвать нашу лямбду:
curl https://XXXXXXX.execute-api.us-east-2.amazonaws.com/dev/hello
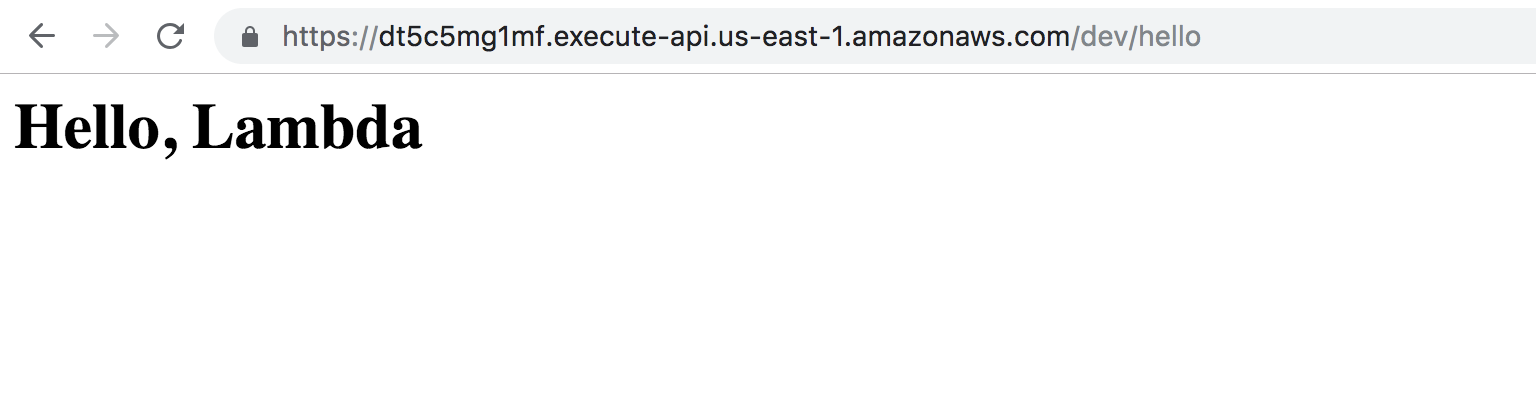
Или мы можем запустить лямбду напрямую и вывести результат работы в консоль с помощью команды invoke:
serverless invoke --function hello --log
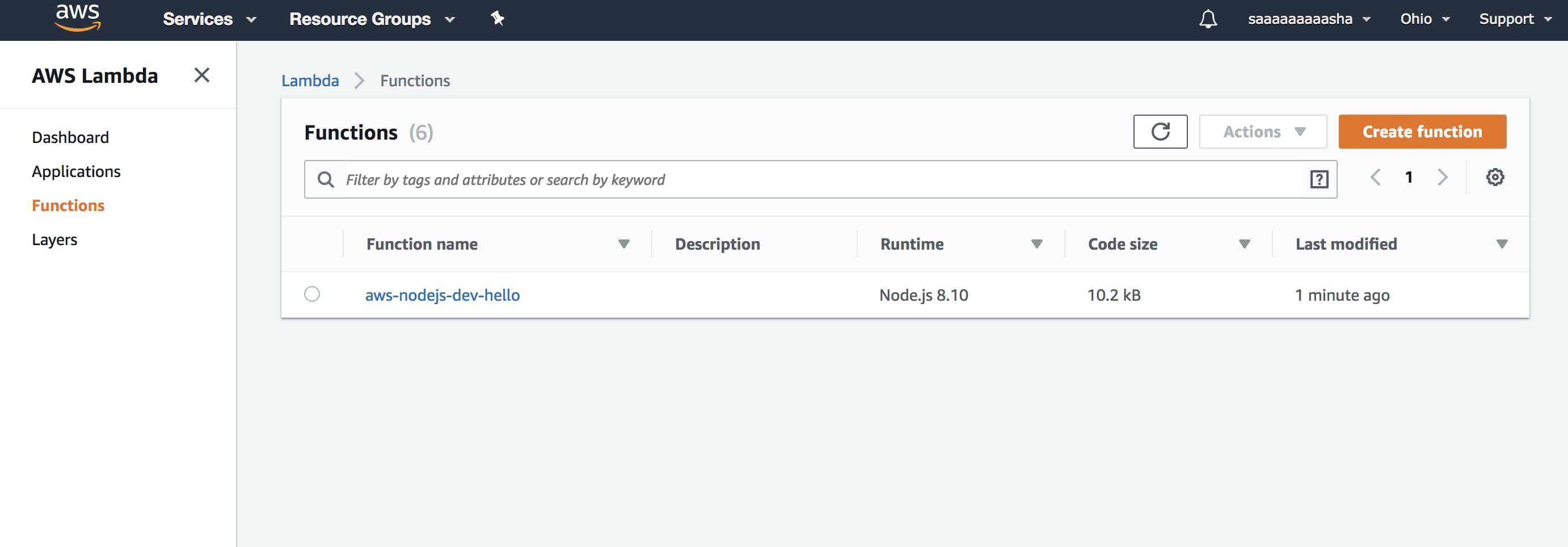
В консоли AWS можно проверить, что функция действительно создалась:
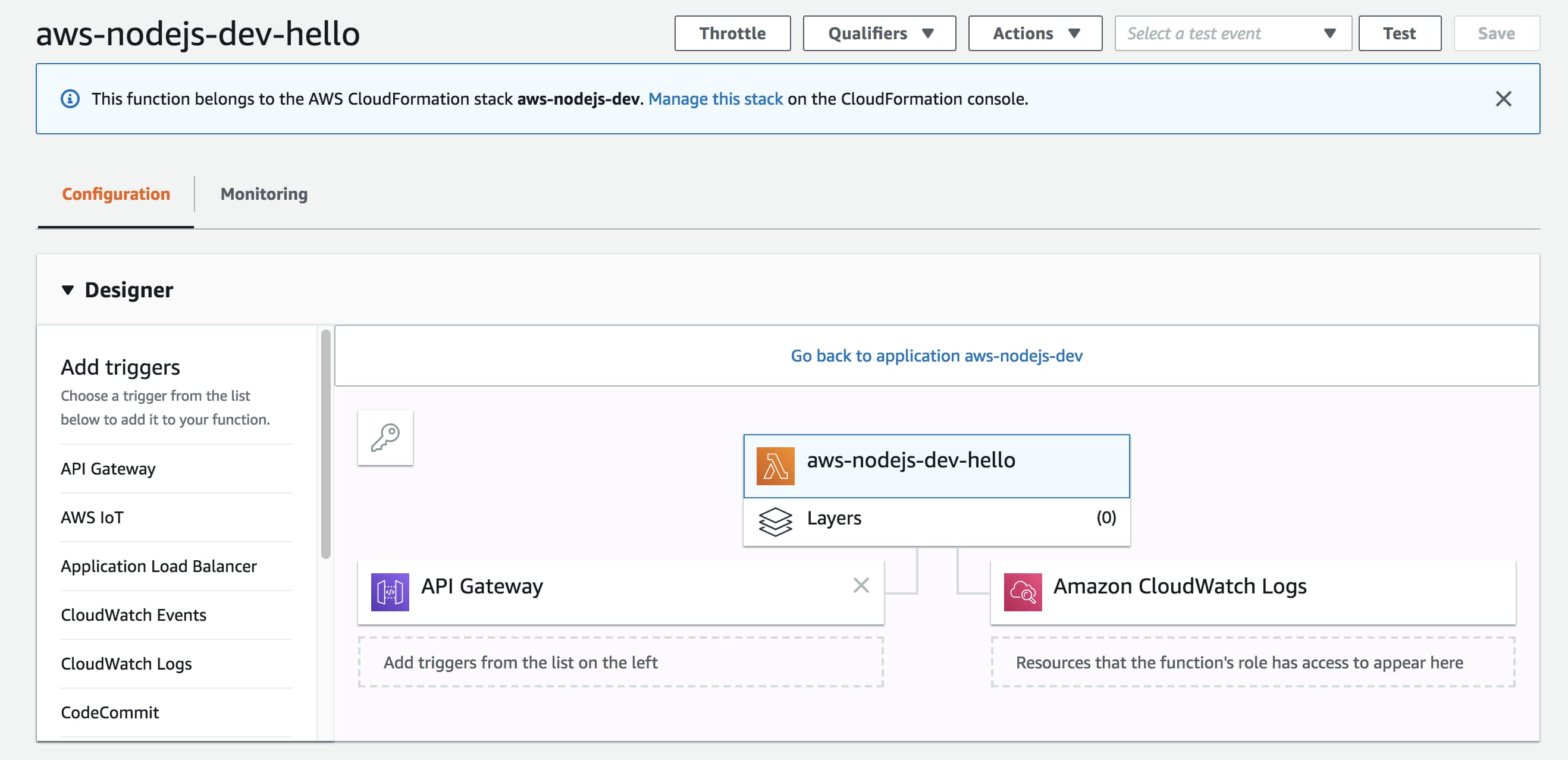
Кроме самой функции создастся вся остальная инфраструктура, которая там описана, в нашем случае это API Gateway:
Когда лямбду захочется удалить, достаточно выполнить:
sls remove
И удалится вся инфраструктура, которая описана в serverless.yml.
Что еще можно сделать на лямбдах? #
Вообще, на лямбдах можно сделать почти все, что и на обычных сервера, от простых порталов (как статических сайтов, так и одностраничных приложений), до сложных процессов с распределением нагрузки. Но лучше всего лямбды конечно же подходят для прототипирования, чат-ботов, IoT (Internet of Things), обработкой файлов и т.п. На лямбдах можно без проблем запустить реакт приложение - рекомендую к просмотру доклад Марины Миронович, где она в качестве примера создает react приложение с серверным рендерингом:
Единственное, если у вас в самом деле большая нагрузка и бигдата, лямбды могут выйти дороже, чем обслуживание обычных железных машин. Но технология находится еще на начальном пути, и со временем будет только расти и развиваться, поэтому попробовать в любом случае рекомендую (тем более амазон на начальных этапах предлагает все попробовать бесплатно). На https://serverless.com/examples/ можно найти много примеров использования и туториалов, а на сайте амазона официальную документацию по лямбдам.