Почему я не использую NextJS
О каких технологиях вы задумываетесь, когда речь заходит о разработке фронтенд проекта, страницы которого должен понимать Google или Yandex (SEO) и данные для которого постоянно нужно запрашивать через API. Например, какой-нибудь ecom (онлайн магазин бургеров). Уменьшим выборку, ваша команда имеет хороший опыт в React.
Я думаю вам (как и мне) на ум сразу приходит NextJS, очень амбициозный фреймворк поверх React-а с кучей лучших DX фич, включая SSR, TypeScript, префетчинг данных по роуту, статическая и гибридная генерация и многое другое (скопировал с офф сайта). Многие мои коллеги используют некст не только для выше описанного кейса, а почти для любого проекта. На гитхабе у библиотеки уже 93k звездочек, активной компанией (NextJS разрабатывают в Vercel, т.е. разработчикам платят за разработку) и с большим сообществом, а это о многом говорит.
Есть сотня статей и постов о том, какой NextJS крутой, есть даже отдельная конференция NextJS Conf, посвященная фреймворку.
Но, как обстоят дела на самом деле? Все ли так радужно и стоит ли без раздумий использовать NextJS при разработке нового проекта?
На самом деле заголовок
немногогромкий, так как на текущем проекте мы используем как раз таки NextJS и при его выборе даже не рассматривали альтернативы, которых к слову не так много (для SSR на React). Поэтому в статье рассмотрим те проблемы, с которыми столкнулся я и моя команда.
File-based роутинг #
У многих решений для генерации статических сайтов (SSG) роутинг сделан на основе файлов системы:
pages
category
[categoryId].ts
index.ts
→→→
/category
/category/{categoryId}
И это оправдано и удобно, так как сразу понятно, какие страницы будут сгенерированы по итогу. Но для серверного рендиринга (и обычного SPA) куда подходящий вариант - это динамический роутинг на основе конфига (или тех же роутов в react-router), чтобы отвязать роутинг от компонента со страницей. Я всегда считал хорошей практикой, что система роутинга максимально абстрагирована от бизнес логики и просто указывает, какой компонент нужно отрендерить.
В NextJS же страница отвечает и за то, откуда она будет доступна, и за получение и генерацию данных, и за кешеривание. Если есть вложенные роуты, то это становится довольно сложно поддерживать. И отказаться от этого подхода нельзя. Если вы не работали с таким подходом, будет сложно к нему привыкнуть.
Из-за роутинга на основе файлов мы не можем для страниц использовать методологию feature-sliced, которая помогает структурировать директории и файлы в проекте. Не можем использовать свои eslint правила для страниц (файл обязательно должен называться index.tsx и в нем нужно обязательно использовать export default для экспорта страниц, даже есть во всем проекте у нас запрещено такое).
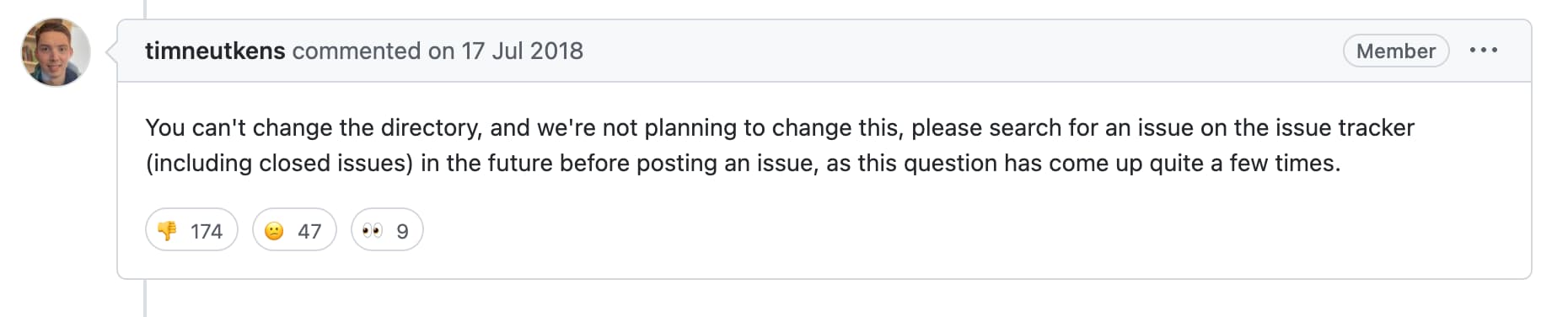
Интересный факт, что года 4 назад, когда я впервые попробовал NextJS, расположение директории pages вообще нельзя было менять и перенести в
src. Есть много старых ишьюсов (например вот этот) по этой теме (так как на 99% проектов весь исходный код лежит именно вsrcи странно было хранить компоненты страниц за пределамиsrc). Разработчики тогда писали, что это не баг и они менять это не будут. По итогу эту фичу конечно же добавили: https://nextjs.org/docs/advanced-features/src-directory .
Работа с данными #
С одной стороны NextJS не ограничивает нас в выборе стейт менеджера, можно использовать любое решение. С другой стороны, у некста несколько своих жизненных хуков для работы с данными на стороне клиента и сервера. И здесь начинается боль.
Для начальной загрузки страницы используется метод getInitialProps, который будет выполняться на сервере. Если делать переход на другую страницу через next/router или next/Link, то этот метод будет запускаться на клиенте. Но если у страницы есть метод getServerSideProps, то метод будет выполняться и на сервере. Это довольно неявное поведение. Или по умолчанию при смене страницы на клиенте всегда вызывается getServerSideProps новой страницы, который за собой может пытаться загрузить уже существующие данные (нужно явно указывать shallow). Да, со временем можно изучить все тонкости, но я уверен, что можно было реализовать более легкий API для использования.
Между методами жизненного цикла (в том числе из-за того, что они выполняются и на сервере, и на клиенте) нет встроенной возможности шарить данные и нужно использовать внешние решения (например, в Redux для синхронизации стейта между сервером/клиентом и правильной гидрации, но об этом ниже).
«Бедная» экосистема #
Несмотря на то, что почти для всех задач уже написаны какие-либо решения, они официально не поддерживаются и как это часто бывает, качество таких библиотек страдает. Но в NextJS это ощутилось более остро. Расскажу про несколько кейсов.
next-transpile-modules #
🎉 Обновление от 26/04/2023: В NextJS 13.1 добавили возможность собирать код из node_modules с помощью свойства
transpilePackages, поэтому данный пункт больше не актуальн.
NextJS не позволяет собирать файлы из node_modules (https://github.com/vercel/next.js/discussions/32223). Зачем вообще нужно собирать что-то из node_modules? Например, для тришейкинга, чтобы не тащить весь пакет. Или, как в нашем случае, для работы с монорепозиторием. У нас в монорепе несколько пакетов (один из них - приложение на нексте) и в режиме разработки было бы очень удобно при изменении кода в каком-нибудь пакете автоматически пересобирать некст-приложение.
Есть решение, которое позволяет собирать перечисленные в конфиге модули - библиотека next-transpile-modules. У нее 1k звездочек и 717k (больше 700 тысяч, Карл!) скачиваний в неделю.
Но если мы зайдем в код библиотеки, мы увидим следующее:
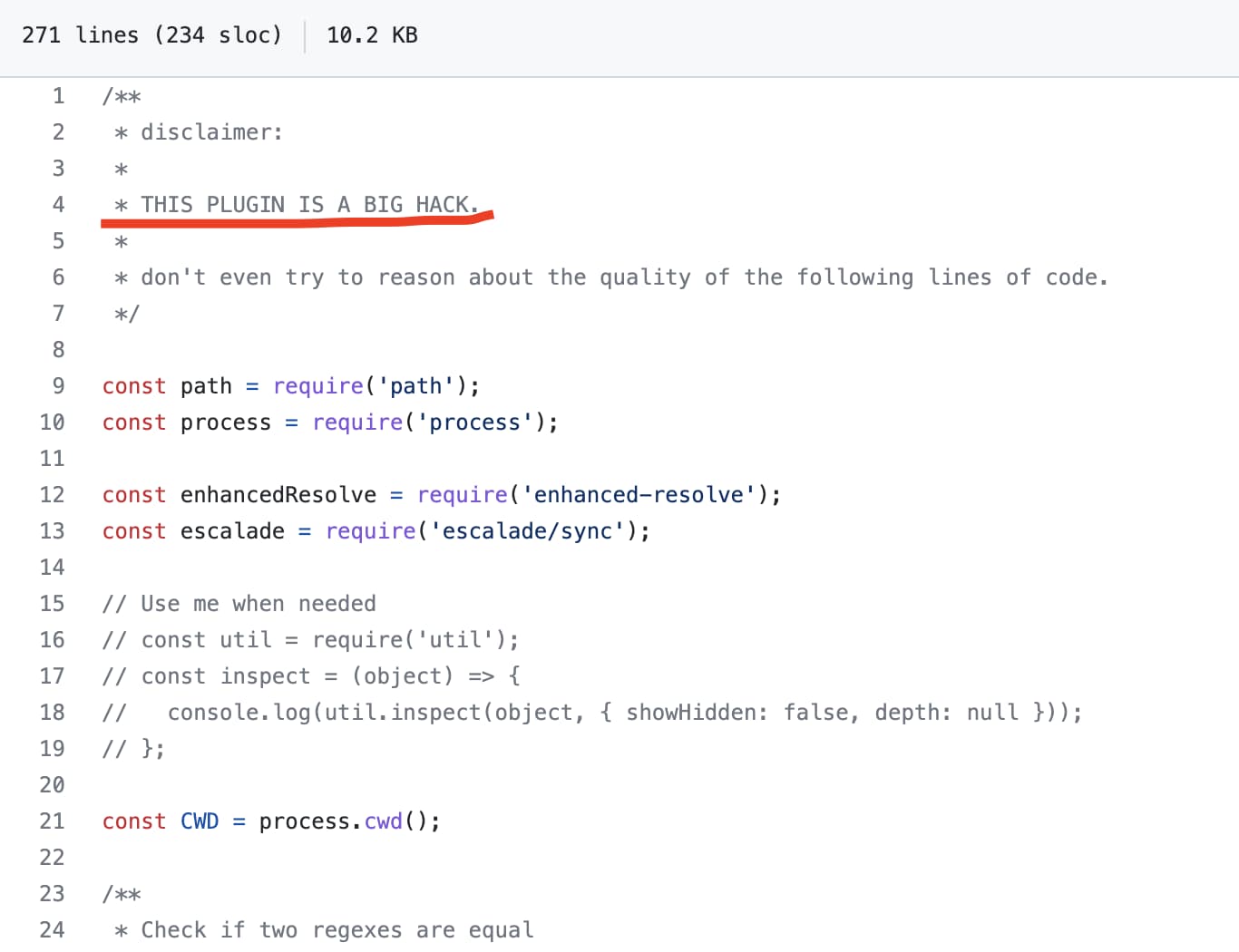
В коде самой библиотеки происходит патчинг лоадеров webpack-а, которые зашиты внутри некста. Т.е. в теории любое изменение разработчиками конфига вебпака в нексте может привести к поломке тысяч приложений. К тому же, используя плагин придется завязаться на использование вебпака, исключив возможность использование других компиляторов/бандлеров. Об этом и говорит автор, что этот пакет является необходимым хаком.
Что сделали мы? Продолжили страдать. Этот плагин использовать не стали, пока просто пересобираем связанные проекты и после перезапускаем некст.
Сейчас есть экспериментальные решения типа флага
externalDir(https://github.com/vercel/next.js/pull/22867), который позволяет импортировать TypeScript файлы за пределами рабочей директории (но это не будет работать с CSS).
next-redux-wrapper #
Следующий кейс, это синхронизация состояния между сервером и клиентом для Redux-а. В клиент-сайд приложениях с редаксом все очень просто, у пользователя в рантайме (в браузере) создается экземпляр со стором и работа идет с ним. В самописных SSR проектах (года два назад я написал большое руководство, как настроить SSR с нуля, рекомендую, если интересно, как работает все изнутри) на сервере создается стор, его сериализованное состояние передается на клиент, которое используется как начальное, и дальше мы работаем как с обычным SPA (single page application).
В NextJS на каждый переход на новую страницу по умолчанию будет вызываться серверный обработчик, создаваться новый стейт на сервере, который просто будет заменять текущий клиентский. По сути при переходе между страницами мы полностью потеряем клиентский стор.
Есть популярная библиотека (240k скачиваний в неделю и 2.3k звездочки на гитхабе), которая решает эту проблему. Библиотека в каждом из методов жизненного цикла некста предоставляет единый инстанс стора и методы для его гидрации с клиентским стором.
Все бы ничего, но у нас при переходе между страницами приложение стало зависать на 4-8 секунд. Начали разбираться. Пошли сначала в React Profiler и увидели, что при смене роута у нас реакт очень много раз ререндерит части приложения и только на тик через 6 секунд доходит до регидрации новой страницы (133 перерендера просто при переходе на другую страницу):
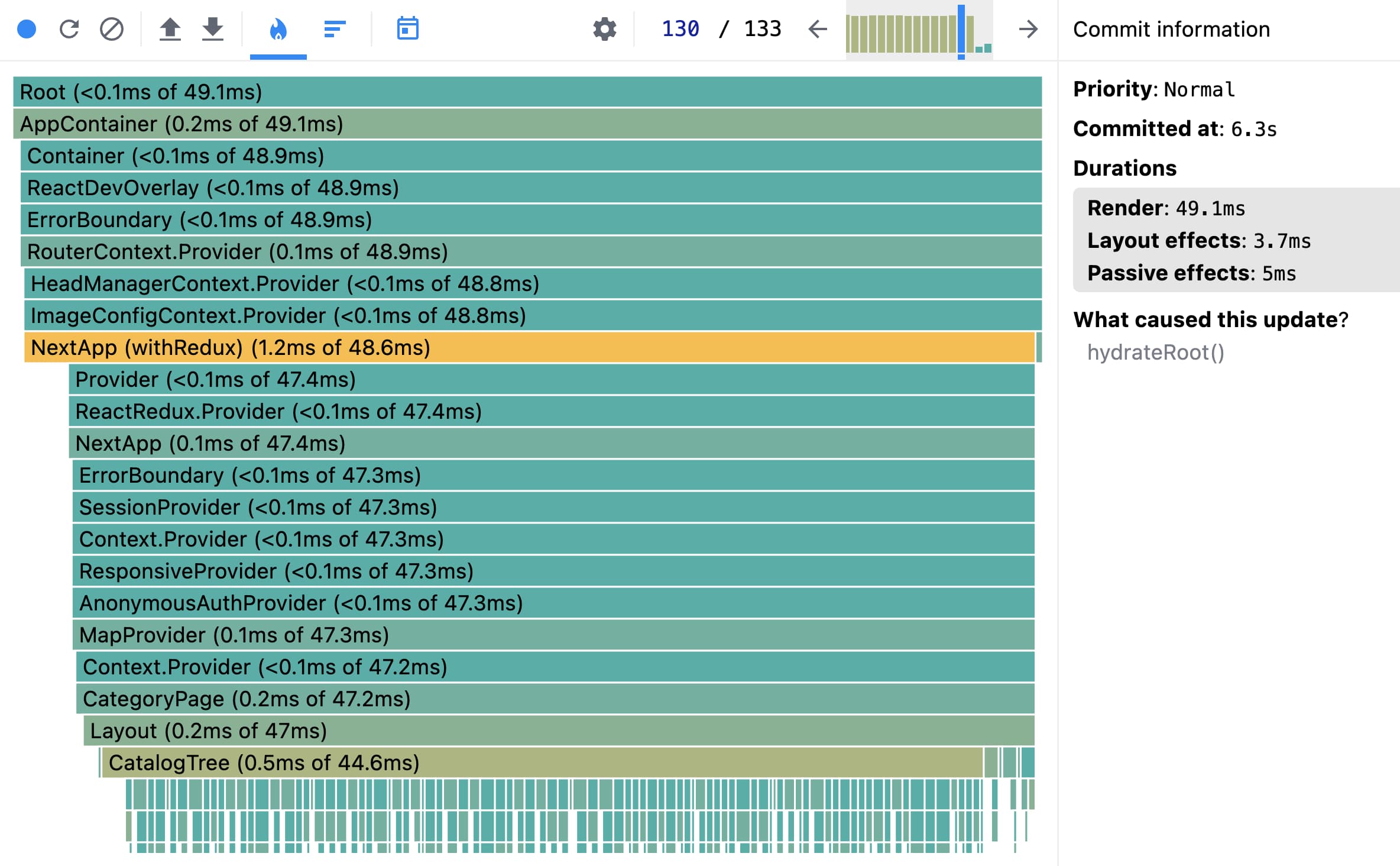
Все ререндеры ДО вызывались непонятно по какой причине и обновляли элементы в списках:
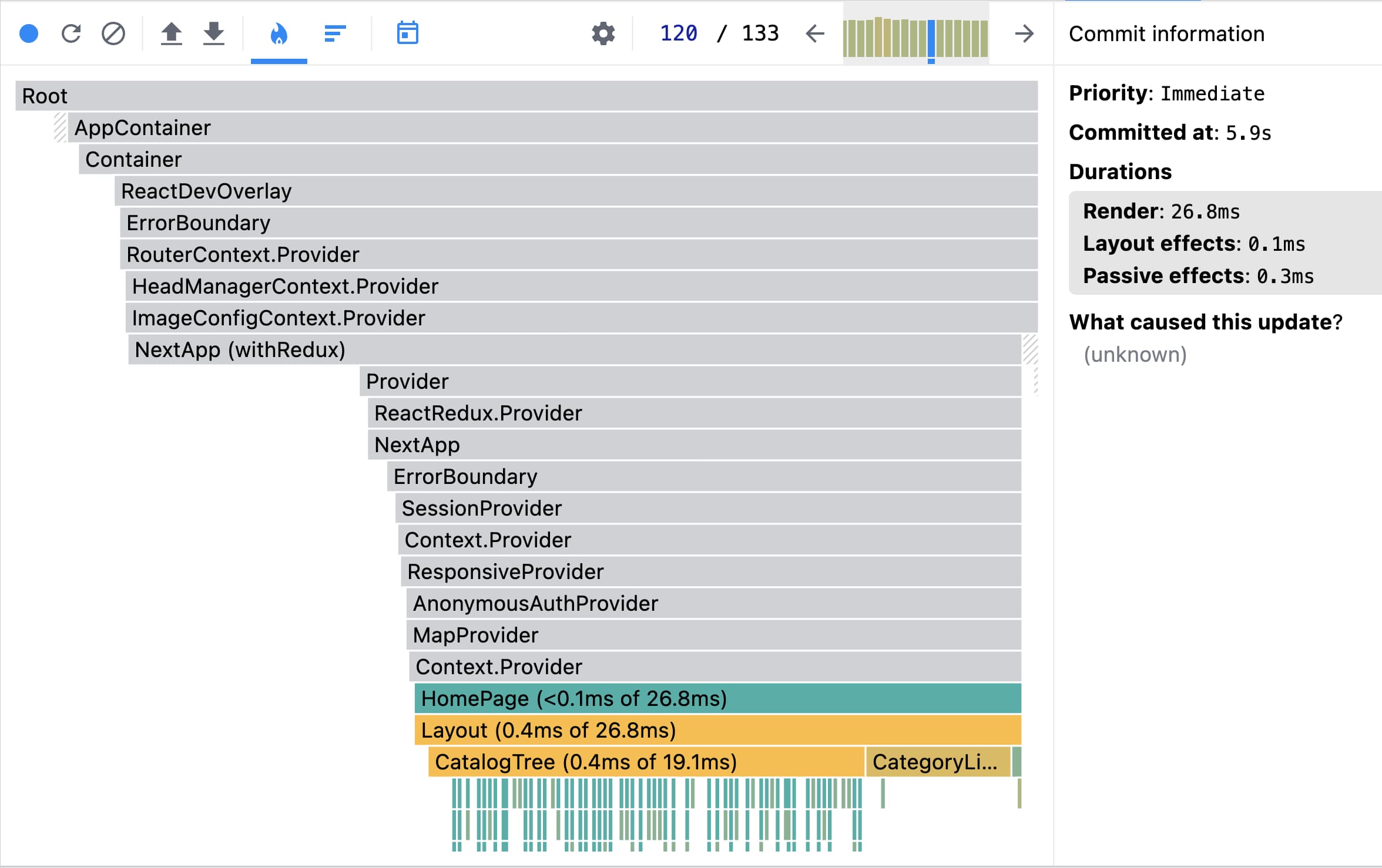
Да, у нас в приложении есть списки, есть много данных в сторах, не все было мемоизировано и мы с понимаем отнеслись к нескольким перерендерам. Но не на 6 секунд ожидания. Далее мы пошли в Performance и вообще ужаснулись:
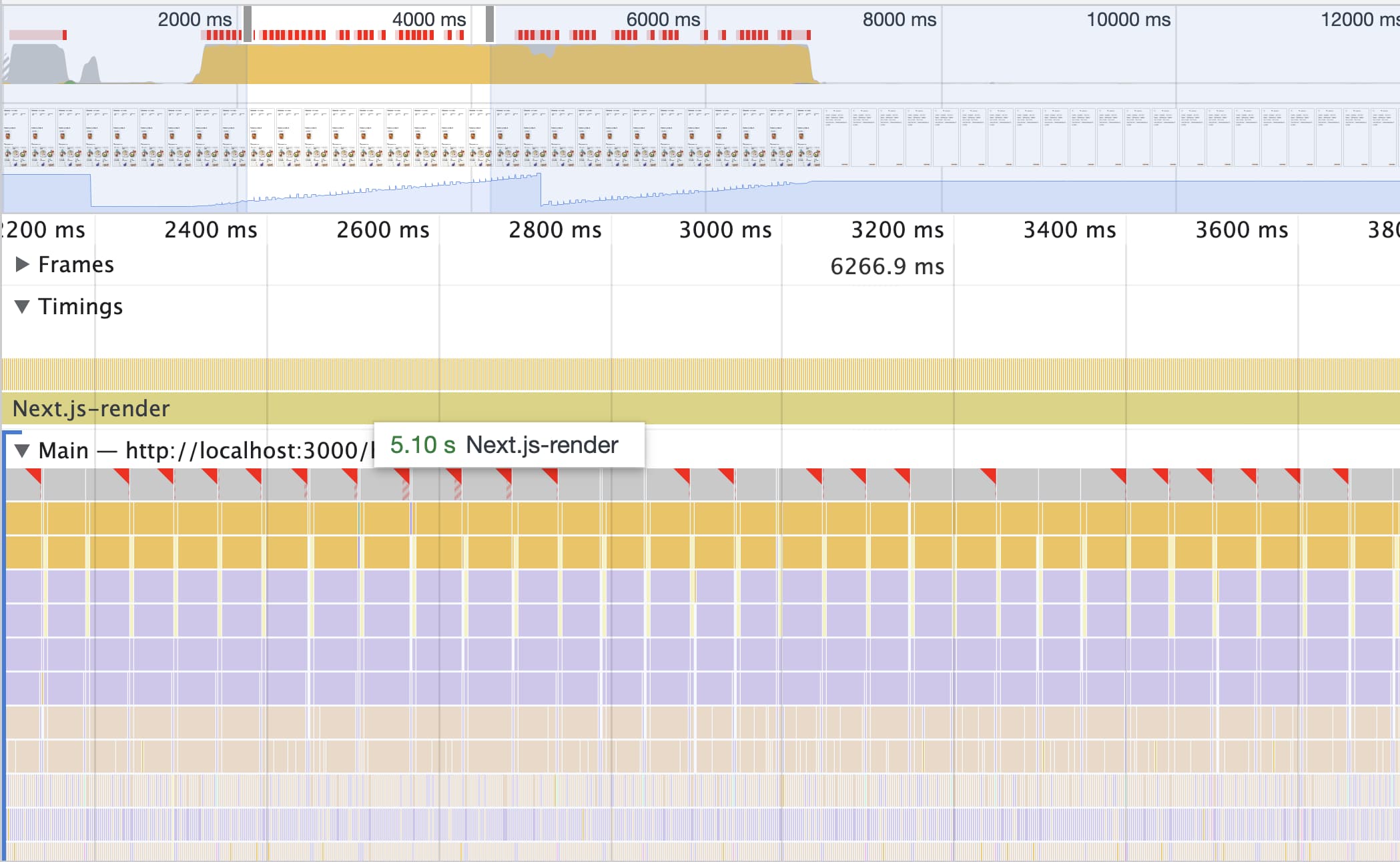
Event loop забит на протяжении 6 секунд ререндерами от next/render. Если там посмотреть глубже, там перерендериваются компоненты с изображениями от next/Image, но по итогу не в них была ошибка.
Проблема оказалась в пакете next-redux-wrapper, который рекурсивно сравнивал стейты редакса и отправлял приложение перерендериваться. Мы нашли пару релевантных ишьюсов (этот или вот этот) и как оказалось, проблема была решена в новой версии, которую опубликовали за пару дней до того, как мы столкнулись с ней. Как те 200k скачиваний в месяц жили с таким багом до его фикса (а это как минимум 1 год), я не представляю. Возможно на более легких проектах (с небольшим количеством компонентов и стором) эти 6 секунд сокращались до нескольких сотен миллисекунд, но все же. И то, баг решился случайно, внутренности были переписаны с классов на хуки (коммит с изменениями, который тоже не так просто было найти).
Если мы раньше стартовали проект, то пришлось бы безумно много времени потратить, что бы найти внутри next-redux-wrapper источник проблемы.
next-auth #
Для OAuth авторизации (и не только) у NextJS есть официально поддерживаемая библиотека next-auth. На сервере после авторизации создается объект сессии (данные хранятся в куках), который отвечает за то, авторизованный пользователь или нет. Все хорошо, до того момента, как нужно чуть-чуть кастомная возможность. В нашем случае, у нас всем пользователям при первом заходе бекенд выписывает токен (т.е. анонимные пользователи). И все, начинаются мучения.
Объект с сессией нельзя программно создать, поэтому пришлось в обход next-auth генерировать токены, сохранять их в редакс сторе и уже вызывать "авторизацию" с клиента. А после логаута явно инициализировать авторизацию анонима. Все это выглядит довольно костыльно.
И на самом деле я соврал, даже если не использовать ничего кастомного, но есть необходимость дополнительно обрабатывать авторизационные токены (например, обновлять их или останавливать очередь запросов до получения актуального токена), то логику авторизации все равно придется дублировать для state-менеджера (в нашем случае для redux-toolkit-query) и next-auth.
Из-за сложности некста, писать свои решения довольно дорого. А со всем готовым из экосистемы, что мы успели попробовать, возникают моменты, которых казалось бы не должно быть.
Неявные зависимости #
Как вы думаете, с чем мы столкнулись первым делом? С установкой зависимостей в CI. У нас в компании (как и во многих компаниях страны, где я работаю) реджестри npm не используется напрямую, зависимости устанавливаются из внутреннего реджестри, который умеет выкачивать пакеты (и указанные в package-lock-ах подпакеты) из npm.
Но NextJS часть зависимостей затаскивает неявно в зависимости от системы пользователя (например, у нас была проблема с версией swc/core), поэтому локально все запускается, а сборка в CI падает из-за того, что не может выкачать зависимости. Пришлось после каждого падения смотреть по логам недостающую зависимость и заливать ее вручную.
Да, это была разовая операция, но такие проблемы на самом старте никогда не бывают приятными.
Самая главная проблема #
Но на мой взгляд, самая главная проблема, что NextJS пытается решить сразу все и быть универсальным решением для всего. NextJS работает и с генерацией статических сайтов (SSG), и с серверным рендерингом (SSR), и просто как с обычным приложением на React (CRA). Обычно проекту требуется что-то одно, а не все подходы сразу. У каждого подхода есть свои устоявшиеся практики, которые отлично показывают себя в одном месте, но не работают в другом. Тот же file-based роутинг отлично работает в SSG, но плохо работает в SSR, где намного удобнее работать с динамическим роутингом (типа react-router-dom). Совмещая все это в одном решении делает саму библиотеку сложной для использования (так как часть API работает только для одного подхода, часть - для другого) и не гибкой.
В то же время из-за этого NextJS дает большую свободу в архитектуре проекта и каждый проект на NextJS будет выглядеть уникально (в плохом смысле этого слова, все же фреймворк предполагает именно единую архитектуру). Да-да, кроме директории pages с роутингом, о котором я уже высказывался отдельно выше.
Поэтому и появляются библиотеки, направленные на решение конкретных проблем (типа Gatsby для генерации статических сайтов), которые выигрывают у некста. Хотя с Gatsby тоже не все прозрачно, но о нем как-нибудь в другой раз.
Что по итогу? #
Основной посыл статьи, который я хотел донести, что не бывает идеальных решений и нужно с большой осторожностью подходить к выбору core-технологий. Хотелось показать, что даже качественные с первого взгляда технологии имеют не мало странностей. Если не согласны и хотите похоливарить, приходить в телеграмм-канал и присоединяйтесь к обсуждению.
Вся статья рассказывает о проблемах, с которыми мы столкнулись только на первом этапе разработки. Уверен, нас ждет еще не мало челленджей (сам я больше всего переживаю на сколько хорошо будет справляться серверная часть приложения при даже небольшом количестве запросов в секунду) когда мы доберемся до прода и реальных пользователей.
Положительные стороны конечно же есть: очень много проблем решено из коробки, с которыми пришлось бы работать вручную без использования NextJS. Выходит много новых фич (та же возможность переключить webpack под коробкой на другой компилятор типа swc), исправляются баги, через неделю будет очередная конференция (если конечно вы читаете этот пост не через пару лет после его написания). Или те же решения, о который я говорил в материале, next-transpile-modules, next-redux-wrapper - их авторы просто красавчики, что сделали за нас огромную работу, которая позволяет использовать нам NextJS.
По итогу, если вам нужен SSG (сайтогенерилка), я бы смотрел на альтернативы, если вам нужно SEO и SSR, я бы оценил, а нельзя использовать CRA или чистый React (с тем же swc или vite) и какой-нибудь пререндер/отдельный SSR только для роботов. В общем я бы сперва хорошенько подумал, а точно ли вам нужен NextJS?