Трофей тестирования фронтенда
О тестировании можно говорить бесконечно долго, начиная с подходов из теоретической части (типа классов эквивалентности и эвристик), и заканчивая взаимодействием разработчиков с QA. Сегодня рассмотрим, что из себя представляет трофей тестирования и какие тесты нужно писать разработчикам в своих фронтенд проектах.
Пирамида тестирования #
Обычно когда речь заходит про тесты, говорят про пирамиду тестирования. По сути это способ визуального отображения, сколько в проекте должно быть тестов каждого вида (слоя):
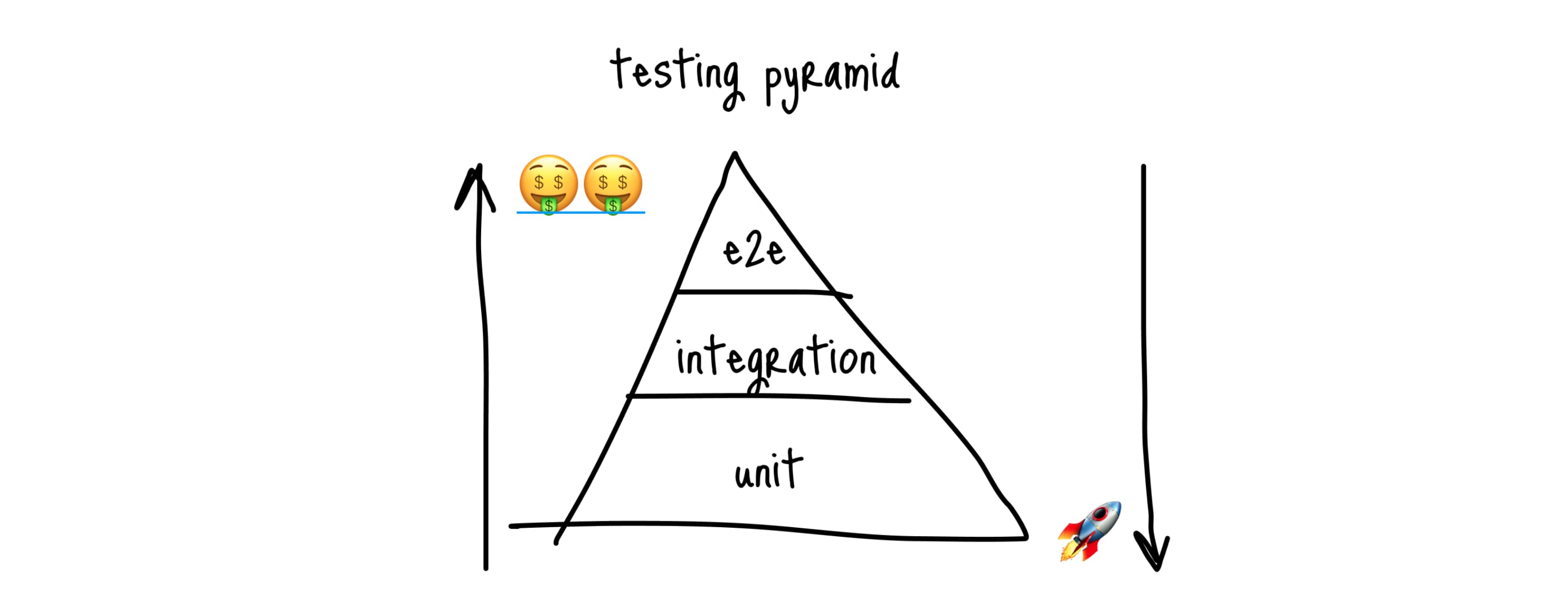
В пирамиде выделяют 3 вида тестов:
- Юнит - тесты на отдельные модули, хелперы, компоненты в изоляции от всего остального приложения;
- Интеграционные - тесты на взаимодействие нескольких модулей, либо UI (но без запуска браузера и реальных сетевых запросов);
- Функциональные (или E2E, или UI) - тесты, когда запускается реальное окружение (браузер, тестовые стенды API) и тест прогоняется на странице в браузере, кликая по кнопкам, заполняя формы и работая с внешними сервисами/API.
Из этой пирамиды главное запомнить две вещи:
- Чем вид тестов находится ближе к вершине, тем тесты полезнее для бизнеса
- Чем ближе к основанию, тем тесты быстрее выполняются, их проще писать и поддерживать
Трофей тестирования #
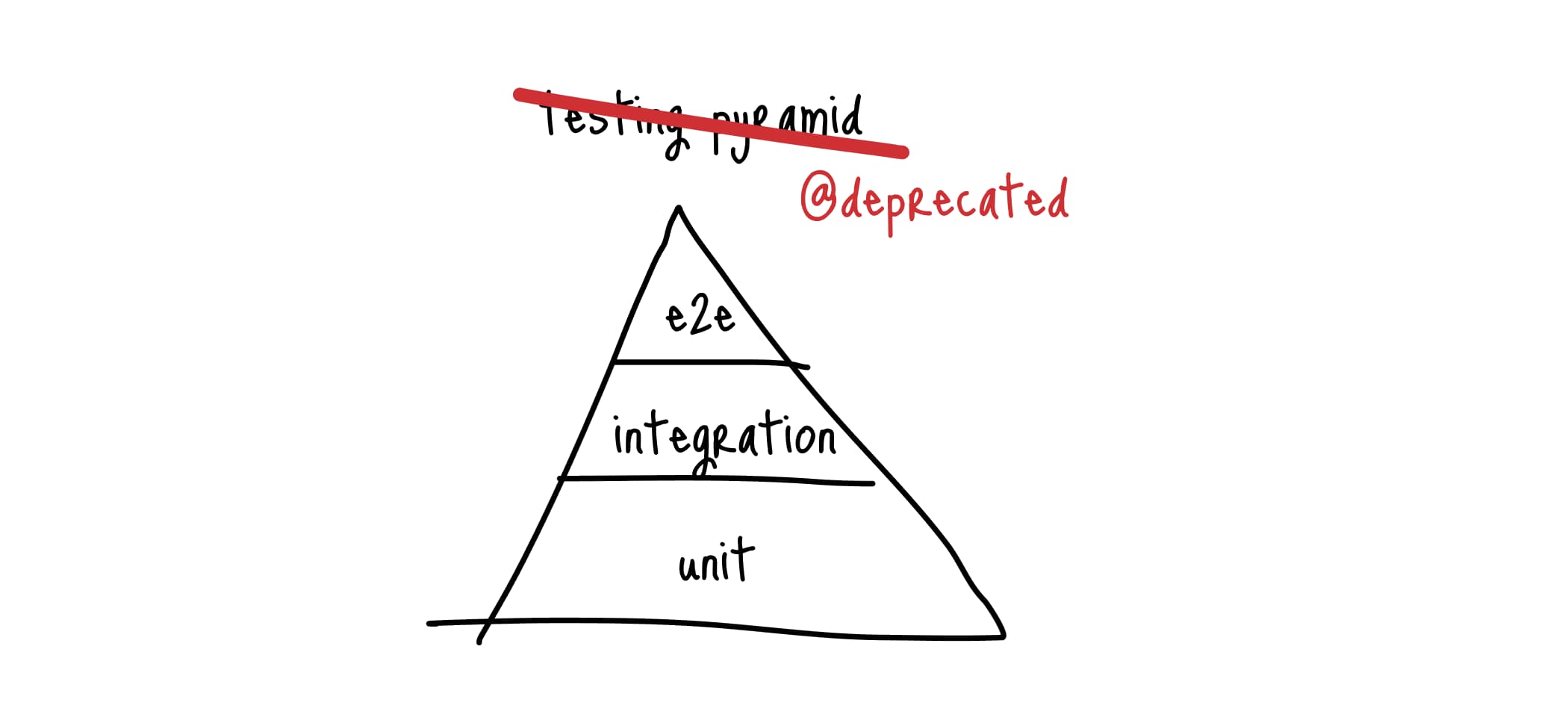
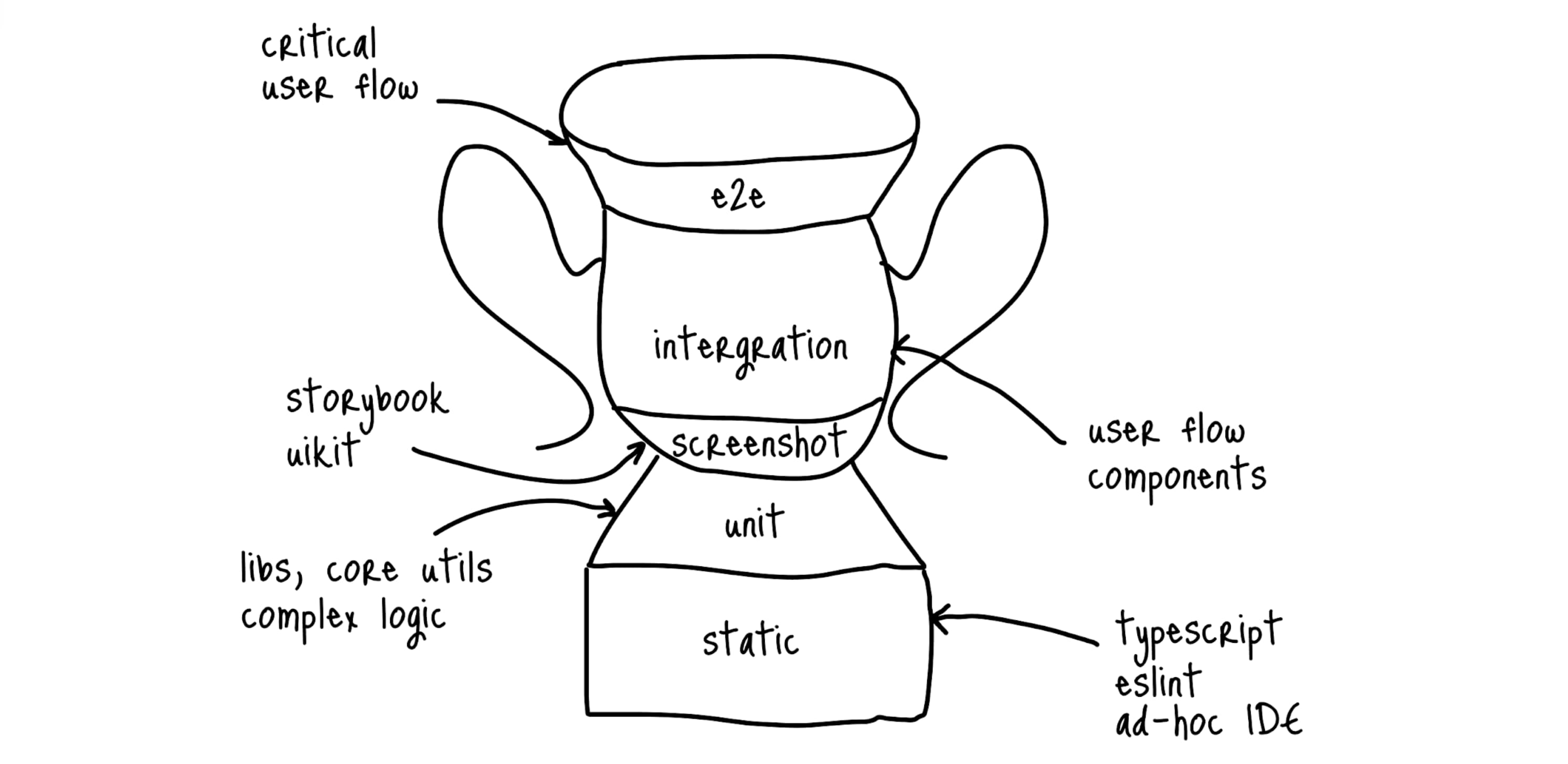
Но что касается фронтенда, мне намного больше нравится визуализация от крутого инженера Kent C. Dodds, который представил так называемый трофей тестирования. В нем сильно изменились пропорции и добавился новый слой - «Статические тесты»:
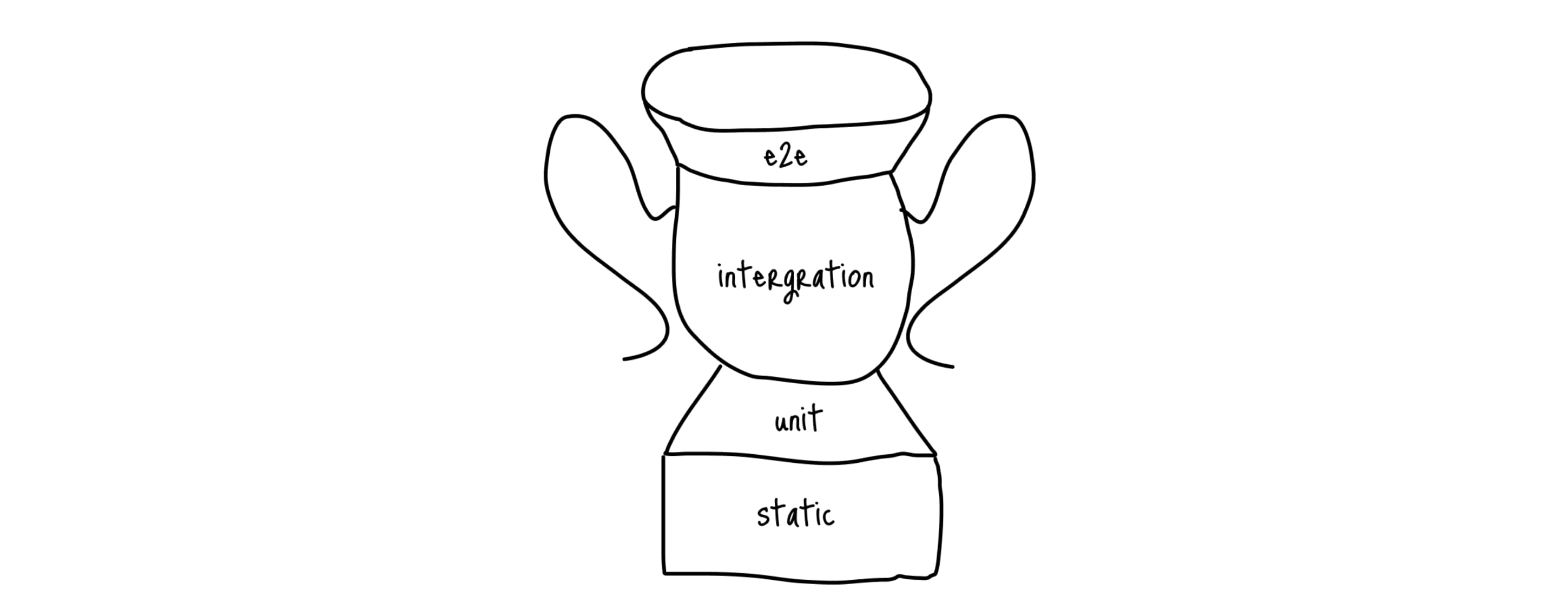
Одна из основных мыслей, которая была заложена в трофей, звучит следующим образом:
Чем больше ваши тесты похожи на то, как пользователи пользуются приложением, тем больше гарантий они могут вам дать.
Если перефразировать, то самые полезные тесты это те, которые повторяют пользовательские сценарии, то, как пользователи пользуются тем или иным функционалом, а не проверка каких-нибудь краевых случаев внутреннего модуля. Но давайте по порядку.
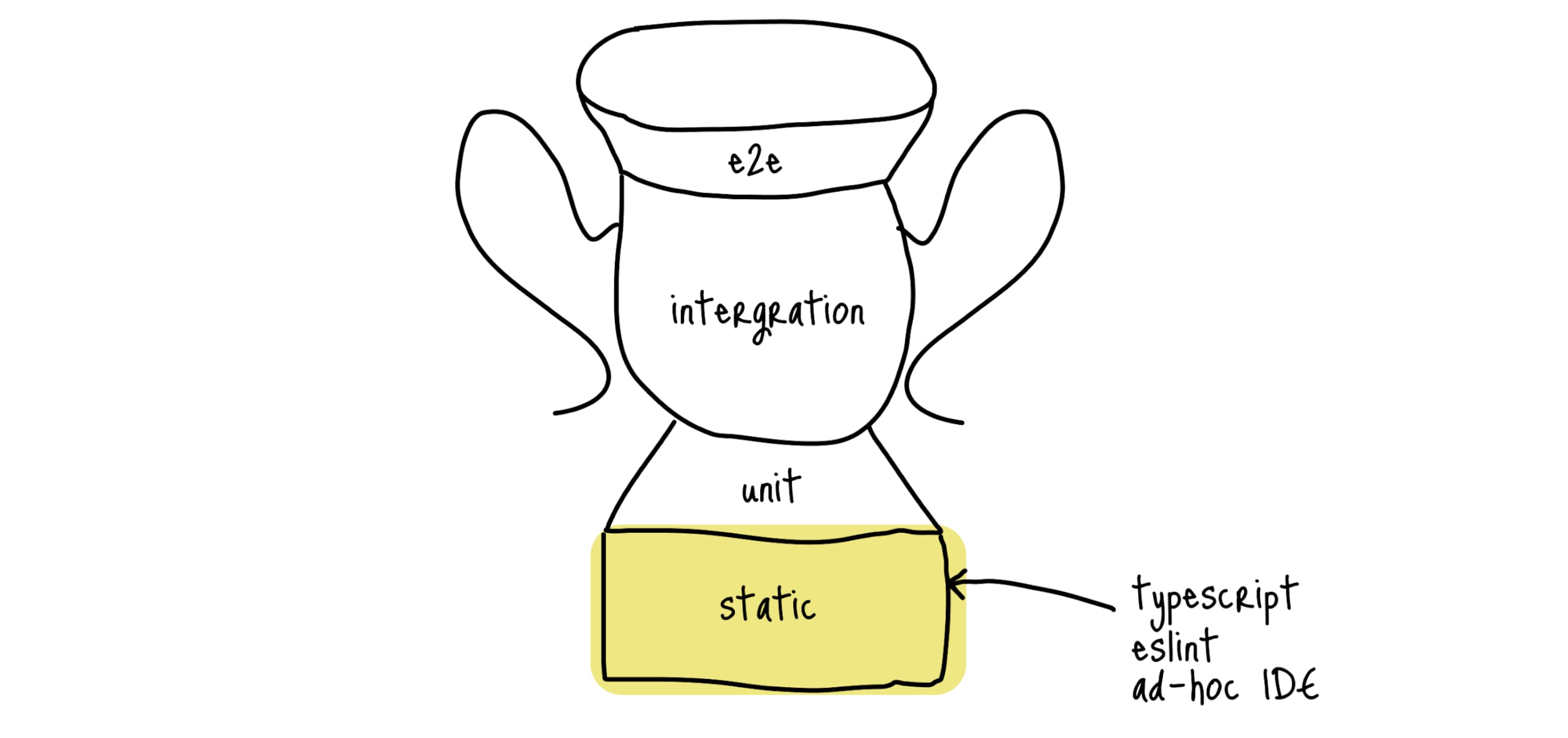
Статические тесты #
Сегодня уже нет смысла доказывать, что TypeScript (или другой аналог со статической типизацией) приносит намного больше пользы в современные проекты со сложной логикой на клиенте, чем его отсутствие. Один из плюсов, TypeScript покрывает огромное количество кейсов, связанных с неверными типами, для которых раньше приходилось писать пачку unit-тестов. Вам очень повезло, если вы не писали такие тесты:
describe('sum', () => {
it('должен как-то работать, если аргумент типа string', () => {})
it('должен как-то работать, если аргумент типа boolean', () => {})
it('должен как-то работать, если аргумент типа number', () => {})
it('должен как-то работать, если аргумент типа object', () => {})
// ...
});
Сейчас же достаточно задавать валидный тип аргументам, и TypeScript уже сам позаботится, чтобы вы не вызвали у строки метод числа, типа 'ops'.toFixed(2).
Так же есть ESLint и IDE, которые позволяют отлавливать синтаксические ошибки. Пропустить скобку, кавычку или использовать переменную до момента ее объявления становится практически невозможно (конечно же возможно, но вы будете об этом уведомлены).
Все это Кент вынес в слой статических тестов:
Юнит тесты #
Следующий слой — это юнит тесты. Пишутся они на изолированные участки кода (функции, методы класса, хуки и т.д.) и выполняются на стороне NodeJS (на самом деле их можно и в браузере запустить, но обычно этого не делают).
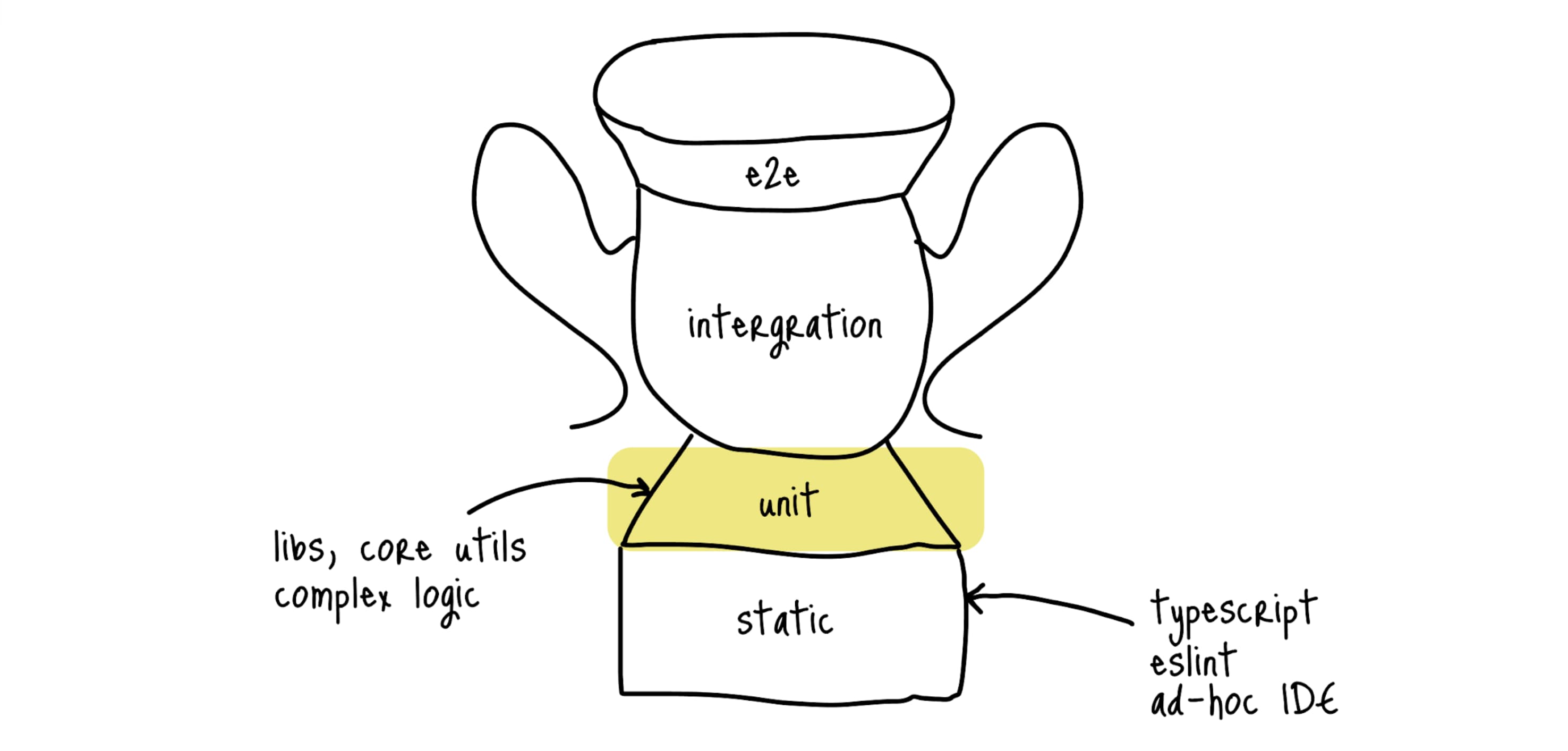
Идеальнее всего они подходят для библиотек и модулей со сложной логикой или с большим количеством состояний.
Важно, чтобы unit-тестов не было много, и не нужно 100% покрытие.
Обычно для юнит тестов прикручивают инструменты, которые позволяют определить, а остались ли в коде логические ветки для которых не написаны тесты. И заставляют разработчиков писать тесты для всего подряд, а так же стремится к 100% покрытию. Не делайте так! В теории это звучит логично, но на практике у вам будет огромная куча тестов, которые ничего не проверяют. Бум. У меня был рабочий проект с 25000 юнит тестами, которые прогонялись за 10 минут (это долго для юнитов, если что); процентов 80% из них были бесполезными (проверяли какие-то синтетические случаи, и были написали только ради зеленой галки в CI).
Вам повезло, если вам ничего не говорит следующий комментарий кода в начале файла:
/* istanbul ignore file */
Это как раз таки одна из библиотек, которая отвечает за покрытие. И весь проект был пронизан подобными комментариями, что бы этот файл/функцию/строчку кода не учитывать в покрытии.
Но тут же отмечу, что это не касается всех проектов. Если вы пишете core-библиотеку или тулзу для разработчиков, которая предполагает использование в других проектах, то максимальное покрытие будет уместным.
Закрепим. Юнит тест подходят для библиотек, core- и сложной логики.
E2E тесты #
Эти тесты больше всего походят на то, как приложение используют пользователи. Почему же не писать только их? Проблем несколько:
- Для их написания нужно настроенное окружение — подготовленые стенды API, предоставляющие тестовые данные
- Такие тесты тяжело писать, отлаживать и поддерживать
- Они ну очень долгие
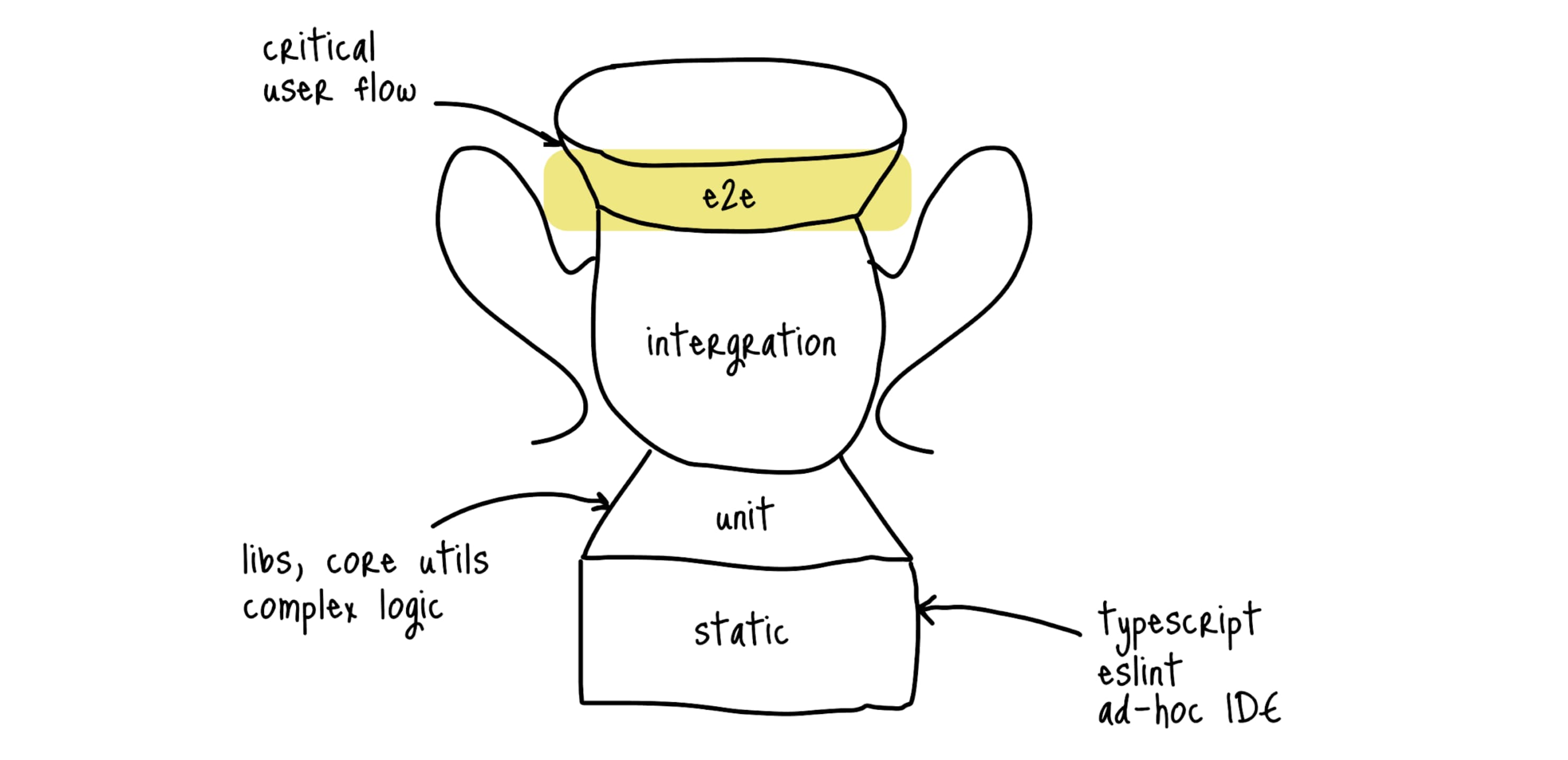
Представьте, что вы хотите протестировать регистрацию нового пользователя. Его нужно создать в базе данных, а что быть со следующим запуском теста (если пользователь уже будет в базе данных)? А что, если один тест запустят два разработчика на своих компьютерах? А если API перепускался и не работал пару минут во время прохождения тестов? Или во время прогона страница не доскролилась до нужного элемента? И это только вершина айсберга, подобных проблем много, и писать честные E2E довольно тяжело.
Поэтому, E2E должно быть еще меньше, чем юнитов, и писать их нужно только для самых критичных сценариев (авторизация, добавление товара в корзину и т.д.). Если у вас нет тестов других слоев, то большой соблазн начать писать именно такие тесты (так как они максимально покрывают пользовательские сценарии). Но остановитесь, лучше начать с интеграционных или юнит-тестов, а E2E оставить на лучшие времена.
Интеграционные #
Кто внимательно рассмотрел трофей тестирования, мог заметить, что интеграционным тестов выделено очень много места (на моей схеме это не так выделяется, извините, но в оригинале их площадь на схеме довольно большая).
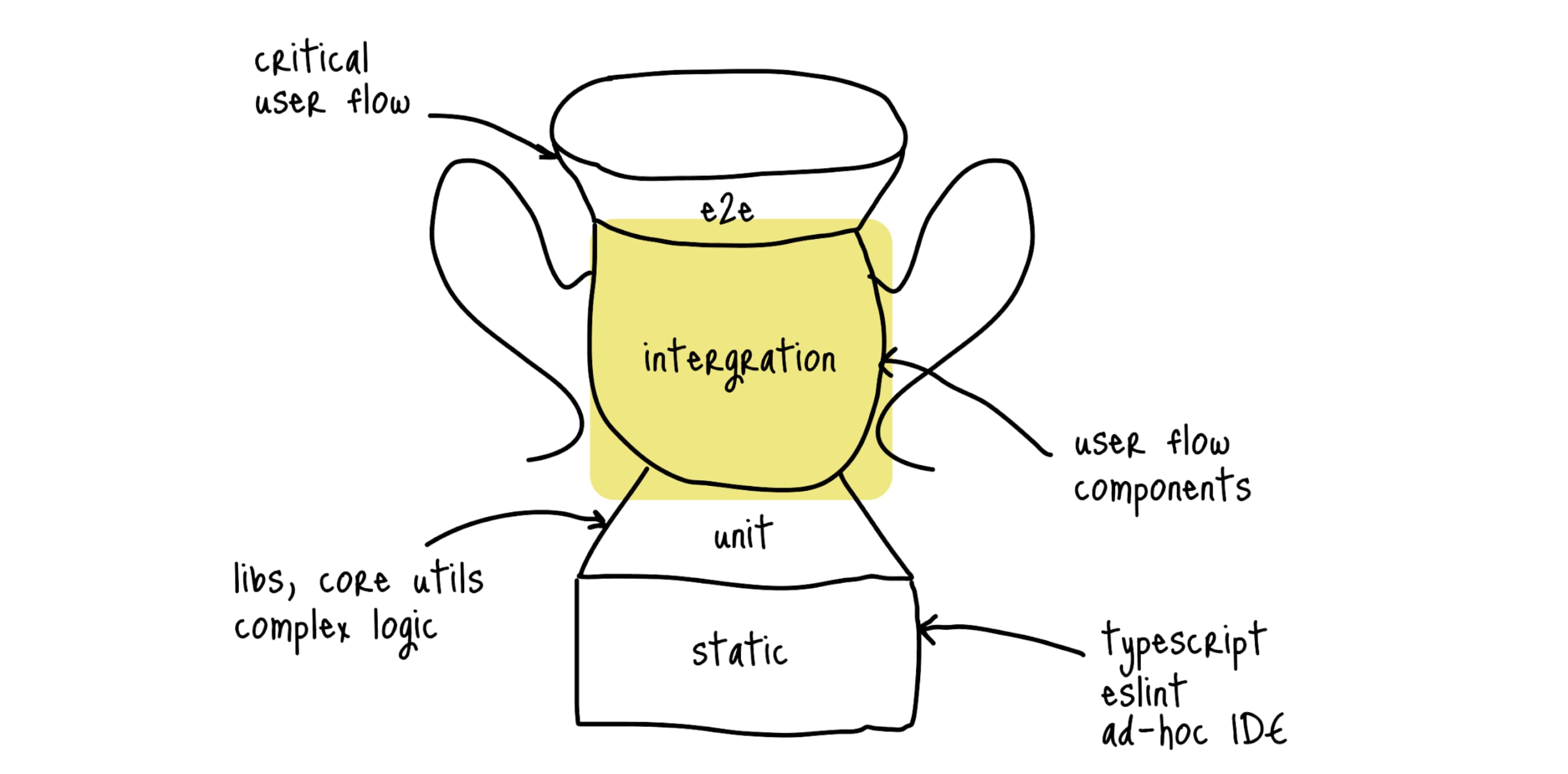
Интеграционные тесты — это тесты, которые позволяют проверять взаимодействие между модулями приложения. В контексте бекенда или сервисной логики это значит тестирование работы модулей. А во фронтенде - тестирование пользовательских сценариев в UI. Так E2E тесты тоже тестируют пользовательские сценарии, чем интеграционные тесты лучше?
Особенность интеграционных тестов заключается в том, что они работают в изолированном окружении (все данные подготовлены заранее). В зависимости от инструментов, тесты так же могут изолироваться от реального запуска браузера, что делает их такими же быстрыми и стабильными, как юниты.
Еще одно преимущество, их можно писать не на все приложение, а на отдельные модули или виджеты. В контексте ныне полуряного микрофронтенда - на конкретный сервис.
Недостаточно? Еще один аргумент в их пользу - они пропагандируют подход black-box тестирования, когда мы не тестируем с разных сторон внутреннюю реализацию (как юниты), а тестуем внешний API модуля, как с ним будут взаимодействовать другие модули или пользователи. Тем самым при изменении внутренней реализации (сохранив внешний интерфейс использования), тесты не придется переписывать. Круто, да?
Самые частные кейсы для написания таких тестов:
- Клик по интерактивному элементу (кнопка)
- Открытие модальных окон
- Заполнение элементов формы и проверка клиентской валидации
- Отправка запроса на бекенд (сам запрос перехватывается и возвращаются замоканные данные) и отображение результата
Писать такие тесты не сложно, но придется сделать не мало подготовительных работ, о которых я расскажу в одном из следующих материалов (а пока материала нет, вы можете послушать часть из моего выступления на митапе, где я рассказываю о шагах, которые нужно сделать, чтобы написать интеграционный тест с использованием testing-library).
Я могу порекомендавать два вида библиотек для таких тестов:
- когда мы не хотим использовать браузер - однозначно testing-library. Очень крутое framework agnostic решение, которое позволяет писать тесты на наш UI
- когда хотим - cypress или playwright, которые так же подходят и для E2E тестов
Скриншотоные #
В интеграционных тестах есть несколько проблем. Одна из них заключается в том, что тесты не покрывают визуальную составляющую. Тест может успешно кликнуть на кнопку, которая скрыта другим блоком или css-стилем. А возможно вообще поехала верстка и UI виджет отображается криво.
Для таких случаев я выделяю еще один слой — скриншотные тесты (еще их часто называют скриншотные юнит-тесты). Делается скриншот UI-компонента (виджета или даже страницы), и все следующие прогоны сравнивают первый скриншот со сгенерированным в текущем прогоне.
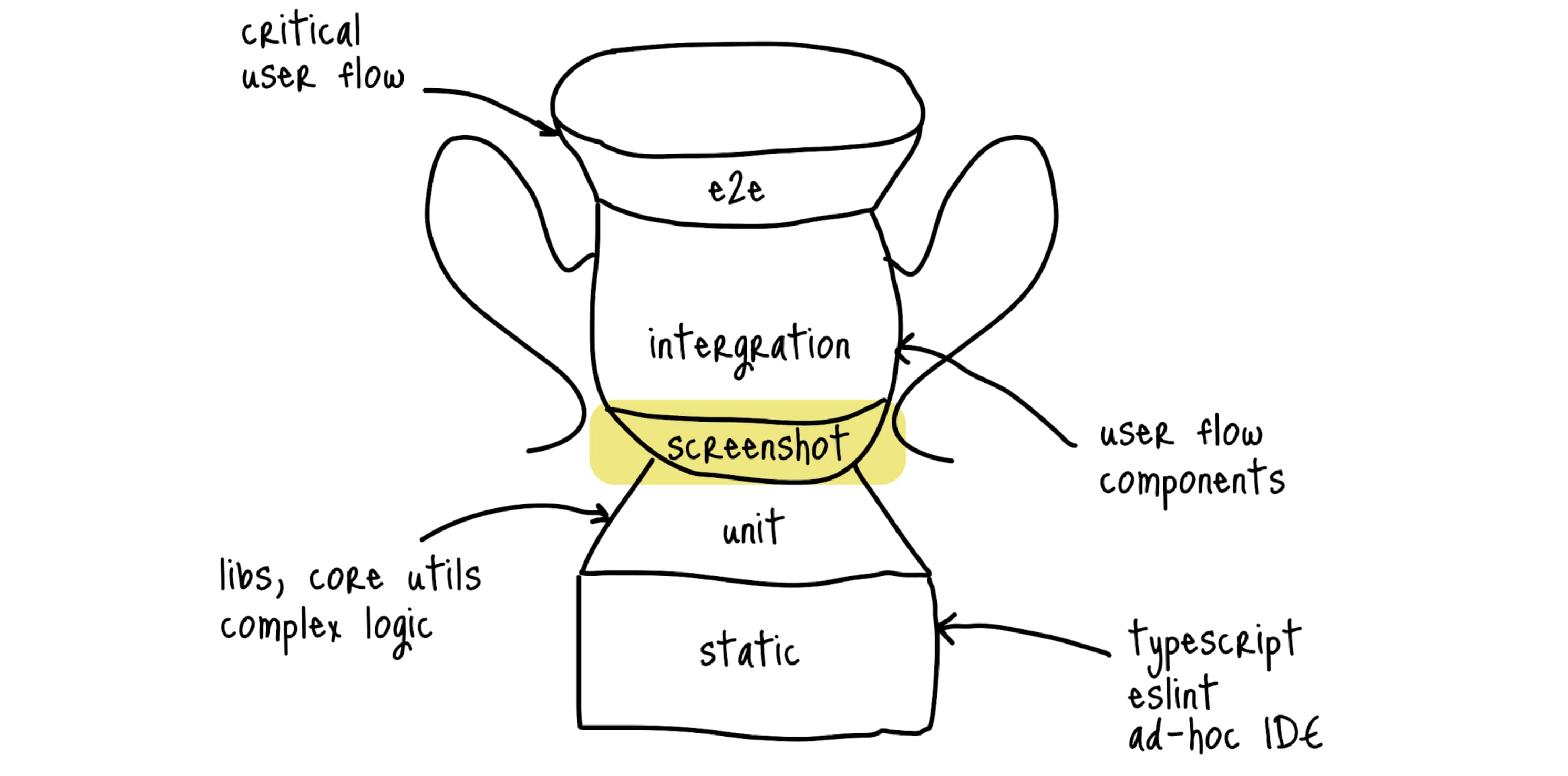
Если у вас есть стенд компонентов (например, Storybook), то идеальнее всего травить скриншотные тесты именно на заготовленные стори. Причем есть довольно много уже готовых решений (например, loki), которые максимально упростят настройку инфраструктуры. У меня в текущем проекте несколько разных сторибуков, для всех них используем скриншотное тестирование (на момент написания статьи это пока в планах).
Вы можете сгенерировать скриншоты под разные брейкпоинты (например те, которые вы поддерживаете в проекте), разные темы (если у вас есть темная) и переключив компоненты в разные состояния. Шик.
Что по итогу? #
Мы прошлись по всем слоям (уровням) трофея и получили идеальный вариант для современного среднестатистический приложения:
Но не стоит забывать, что все очень сильно зависит от вашего проект (системная библиотека, долгоиграющий продукт или стартап), и в вашем случае идеальный трофей будет выглядеть совсем по другому.
Что я вам рекомендую сделать? Нарисуйте трофей вашего текущего проекта, устраивает ли он вас? А может какие-то слои слишком выделяются или их вообще нет? Ниже я нарисовал трофеи для последних трех рабочих проектов, на которых я работал:
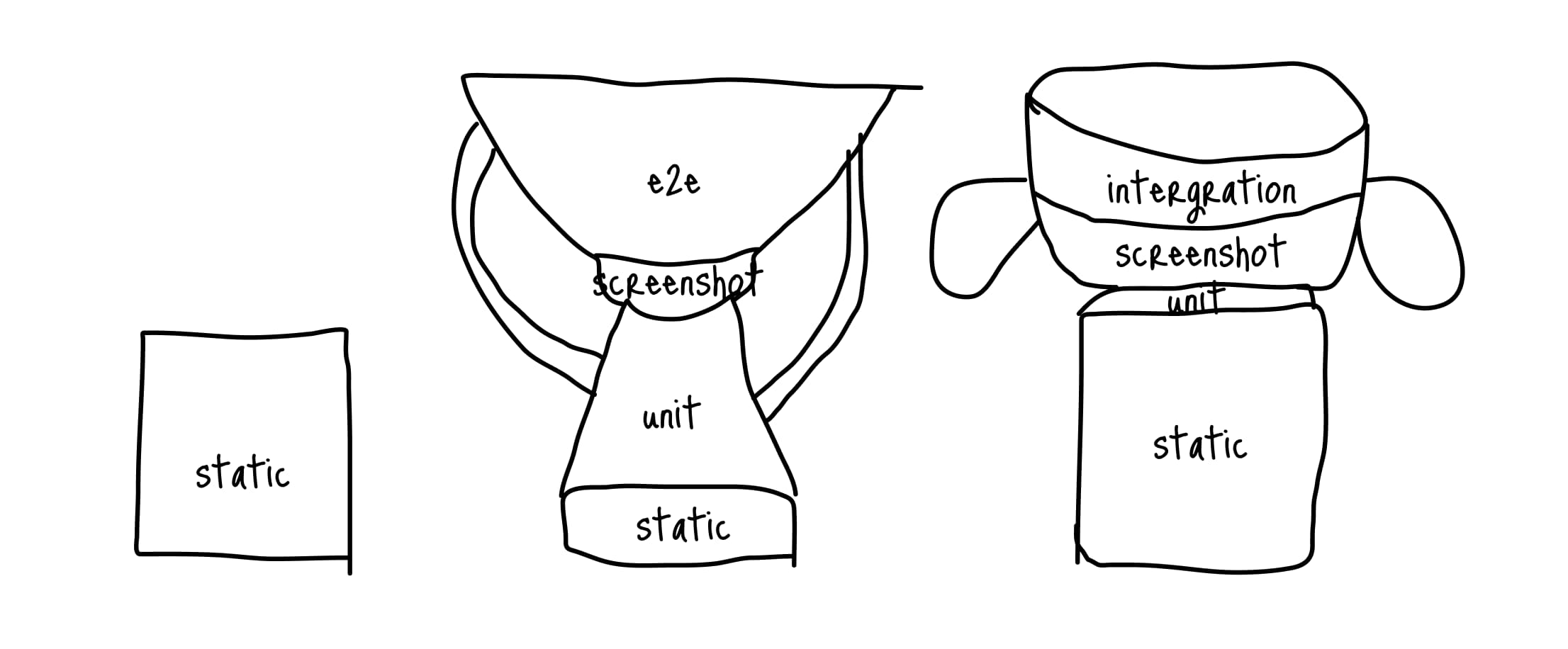
В одном (справа), мы очень строго покрываем все TypeScript-ом (в проекте у нас нет ни одного any и пару @ts-expect-error), но совсем нет E2E тестов (из-за сложности подготовить тестовое окружение). Так же этот проект запускался в довольно сжатые сроки (совсем не до E2E тестов), поэтому в таких рамках - этот вариант трофея близок к идеальному.
В другом (средний) — очень много E2E и unit-тестов. Проект огромный, поддерживается сразу 6 командами, поэтому E2E помогают отловить многие ошибки интеграций. Но если быть честным, 80% тестов (что E2E, что юнитов) бесполезные, поэтому этот вариант для этого проекта не оправдал себя. Нужно добавлять интеграционные тесты и сильно сокращать текущие выпуклые слои.
И еще один проект (слева) имеет только статический слой. Как бы я хотел, чтобы это было осознанно (что это стартап, нужно срочно проверить гипотезу и нет времени на тесты). Но, к сожалению, это был очень важный проект — мобильное приложение на тысячи пользователей, на котором просто никто не писал тесты (включая меня). В этом случае трофей квадрат (если его можно так назвать) совсем не подходит к проекту. Нужно начинать писать тесты (хоть какие-нибудь), так как изменять функциональность на проекте очень сложно, много зависимых кейсов ломаются, а проверок для них нет.
А что получилось у вас?